
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- GA4
- 벚꽃
- 채용공고
- 영화 올드 줄거리
- 수명예측 인공지능
- 미라클 모닝
- 티스토리
- 데이터문해력
- 니다
- 구글애널리틱스4
- 코오롱베네트
- 구글애널리틱스
- 감사인사
- 기사스크랩
- 벚꽃개화시기
- 프로그래머스
- Google Analytics
- 데이터 분석
- Python
- GA
- 명상
- ㅂㅂ
- 독서
- 6시 기상
- 얼음여왕
- 알파줄거리
- 코딩
Archives
- Today
- Total
Data Analyst KIM
[ML] Kaggle_뇌졸중 데이터를 활용한 분류모델 만들기(불균형데이터,SMOTE) 본문
반응형
Cerebral Stroke Prediction-Imbalanced Dataset
Identify Stroke on Imbalanced Dataset
www.kaggle.com
1. 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from sklearn.impute import KNNImputer #Imputation
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")2. 데이터 확인
df = pd.read_csv('dataset.csv')
df.info()
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='stroke',data=df)
plt.title("Imbalanced data")
plt.show()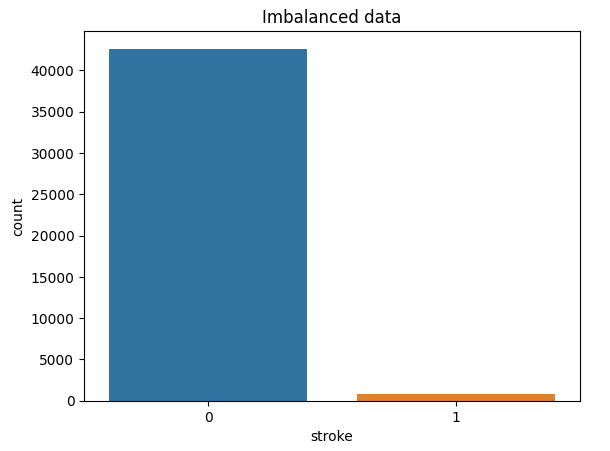
print('Target class is ', '{0:0.4f}'. format(783/(42617+783)*100), '%')<Target class is 1.8041 %>
3. 데이터 전처리
- 인코딩 - 원핫
- 결측값 처리 - KNNInputer
- 스케일링 - 정규화
# 인코딩
df = pd.get_dummies(df,columns=['gender','ever_married','work_type','Residence_type','smoking_status'])
# 결측값 처리
imputer = KNNImputer(missing_values=np.nan)
tab = imputer.fit_transform(df)
df_new = pd.DataFrame(tab, columns=df.columns)
# target 분리
X = df_new.drop('stroke',axis=1)
y = df_new['stroke']
# 스케일링
from sklearn.preprocessing import MinMaxScaler
MM = MinMaxScaler()
X = MM.fit_transform(X)4. 데이터셋 분리
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1)
print("X_train.shape : ", X_train.shape)
print("y_train.shape : ", y_train.shape)
print("X_test.shape : " ,X_test.shape)
print("y_test.shape : " ,y_test.shape)
5. 모델링
5-1. 불균형 데이터 그대로
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from lightgbm import LGBMClassifier
dt = DecisionTreeClassifier()
rf = RandomForestClassifier()
lr = LogisticRegression()
kc = KNeighborsClassifier()
svc = SVC()
gbc = GradientBoostingClassifier()
lgv = LGBMClassifier()
models = [dt,rf,lr,kc,svc,gbc,lgv]
for model in models:
print("MODEL NAME:",model)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred))
5-2. 오버샘플링
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=1)
X_sm,y_sm = sm.fit_resample(X,y)
X_train,X_test,y_train,y_test = train_test_split(X_sm,y_sm,test_size=0.2,random_state=1)
dt1 = DecisionTreeClassifier()
rf1 = RandomForestClassifier()
lr1 = LogisticRegression()
kc1 = KNeighborsClassifier()
lgv1 = LGBMClassifier()
models = [dt1,rf1,lr1,kc1,lgv1]
for model in models:
print("MODEL NAME:",model)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred))
5-3. 언더샘플링
from imblearn.under_sampling import RandomUnderSampler
us = RandomUnderSampler(random_state=1)
X_us,y_us = us.fit_resample(X,y)
X_train,X_test,y_train,y_test = train_test_split(X_us,y_us,test_size=0.2,random_state=1)
dt2 = DecisionTreeClassifier()
rf2 = RandomForestClassifier()
lr2 = LogisticRegression()
kc2 = KNeighborsClassifier()
lgv2 = LGBMClassifier()
models = [dt2,rf2,lr2,kc2,lgv2]
for model in models:
print("MODEL NAME:",model)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred))
6. 최종 모델 = 오버샘플링한 모델

반응형
'데이터 분석 > ML | DL | NLP' 카테고리의 다른 글
| [DL/NLP] 문서 분류 모델 만들기(영화 리뷰 감성 분석) (0) | 2023.11.06 |
|---|---|
| [Deep Learning] 전이 학습(transfer learning) : 치매 환자 분류하기 (0) | 2023.10.27 |
| [Deep Learning] 이미지 증강 : MRI 뇌 사진을 통한 치매 환자 예측 (0) | 2023.10.27 |
| [Deep Learning] 오토인코더(Auto-Encoder)란 무엇인가? (0) | 2023.10.26 |
| [Deep Learning] GAN이란 무엇인가? (0) | 2023.10.26 |
'데이터 분석/ML | DL | NLP' Related Articles
more



